Архитектура балансировки нагрузки
Ограничения архитектурного решения
-
Все сервисы запускаемые в kubernetes кластерах соответствуют Cloud Ready подходу и являются stateless;
-
Сервисы баз данных (реляционные и нереляционные), предоставляются сторонним департаментом как сервис и не должны учитываться в построении active-active конфигурации kubernetes кластеров;
-
Кэширующие сервисы, предоставляются сторонним департаментом как сервис и не должны учитываться в построении active-active конфигурации kubernetes кластеров;
-
Сервисы объектного хранения blob данных, предоставляются сторонним департаментом как сервис и не должны учитываться в построении active-active конфигурации kubernetes кластеров;
-
Единая интеграционная шина предоставляются сторонним департаментом как сервис и не должны учитываться в построении active-active конфигурации kubernetes кластеров;
-
Пожелание заказчика - рассмотреть возможность использования Cilium Cluster Mesh технологии для построение active-active конфигурации kubernetes кластеров;
-
Имеющиеся StatefulSet приложения рассмотреть отдельно в индивидуальном порядке, для запуска в active-active конфигурации kubernetes кластеров.
Задача
Организовать active-active подход между двумя дата-центрами для kubernetes-кластеров с запущенными в них информационными системами. Балансировка и переключение(failover) осуществлять автоматически, при выходе из строя компонентов кластера или информационной системы.
Предполагаемая бизнес задача - обеспечить функционирование критически важных для бизнеса ИС: минимизация простоев, обеспечение должной производительности.
Высокоуровневый архитектурный паттерн
Задачу обеспечения отказоустойчивости можно разделить на подзадачи:
- Обеспечение синхронизации конфигураций (Управление конфигурацией);
- Обеспечение переключения трафика и балансировка нагрузки между дата-центрами (Балансировка нагрузки);
- Обеспечение проверки жизнеспособности приложений.
Вопросы(подзадачи) за пределами текущей проработки:
- Контроль необходимых вычислительных мощностей в обоих дата центрах;
- Интеграции с внешними системами (AD/LDAP, SIEM, ETL, …);
- Вопросы информационной безопасности;
- Split-brain и ложные срабатывания;
- Синхронизация данных информационных систем (Архитектура ИС/приложений);
- Liveness-probes бизнес метриками на уровне приложений выходят за рамки построения active-active конфигурации kubernetes кластеров.
Управление конфигурацией
Проблема
Возможна рассинхронизация конфигураций обособленных кластеров, версий приложений и их конфигураций, вследствие человеческого фактора, misconfiguration или технических сбоев.
Решение
С целью решения проблемы infrastructure drift, будут задействованы подходы IaC и gitops.
Infrastructure drift - рассинхронизация конфигураций кластеров, конфигурации запущенных приложений и версий запущенных приложений.
IaC (Infrastructure as Code) - описание инфраструктуры как код с поддержкой версионирования.
GitOps - подход и набор инструментов, который позволяет синхронизировать конфигурации и версии приложений в соответствии с заранее заданными параметрами, такие как стенды/среды, версии приложений, версии данных и структур.
Балансировка нагрузки между двумя дата центрами с установленной платформой “Боцман”
Cilium Cluster Mesh
Описание
Cilium Cluster Mesh позволяет объединить несколько кластеров, том числе географически разнесенных в одну mesh сеть. Это позволяет решать задачи по отказоустойчивости запущенных сервисов, их масштабированию, балансировки нагрузки между несколькими кластерами и изоляции отказов отдельно взятых сервисов.
Платформа “Боцман” позволяет организовать Cluster Mesh сеть между несколькими кластерами.
Минусы
Cilium Cluster Mesh хорошо подходит для обеспечения отказоустойчивости на уровне сервисов внутри нескольких кластеров Kubernetes, но не решает задачи внешней терминации и балансировки трафика. Данная задача может быть решена с использованием связки Cluster Mesh + BGP или предложенное ниже решение Cluster Mesh + HAProxy + VRRP.
Наши рекомендации
При использовании mesh сети, возможна ситуация, когда компоненты одной ИС будут взаимодействовать между собой, находясь в разных кластерах, создавая при этом дополнительную нагрузку на сети передачи данных между дата-центрами и приводить к дополнительным задержкам. Необходимо настроить “приоритезацию” коммуникаций между сервисами через Topology Aware Routing и настроить следующие аннотации:
- io.cilium/global-service=true - необходим для включения подхода Global Services.
- io.cilium/service-affinity: none - не использовать affinity и балансировать трафик все ко всем между ДЦ.
- io.cilium/service-affinity: local - предпочтительнее использовать локальные экземпляры сервисов внутри одного ДЦ.
- io.cilium/service-affinity: remote - предпочтительнее использовать экземпляры сервисов из другого ДЦ.
Диаграмма с Cilium Cluster Mesh
VRRP + HAProxy
Описание
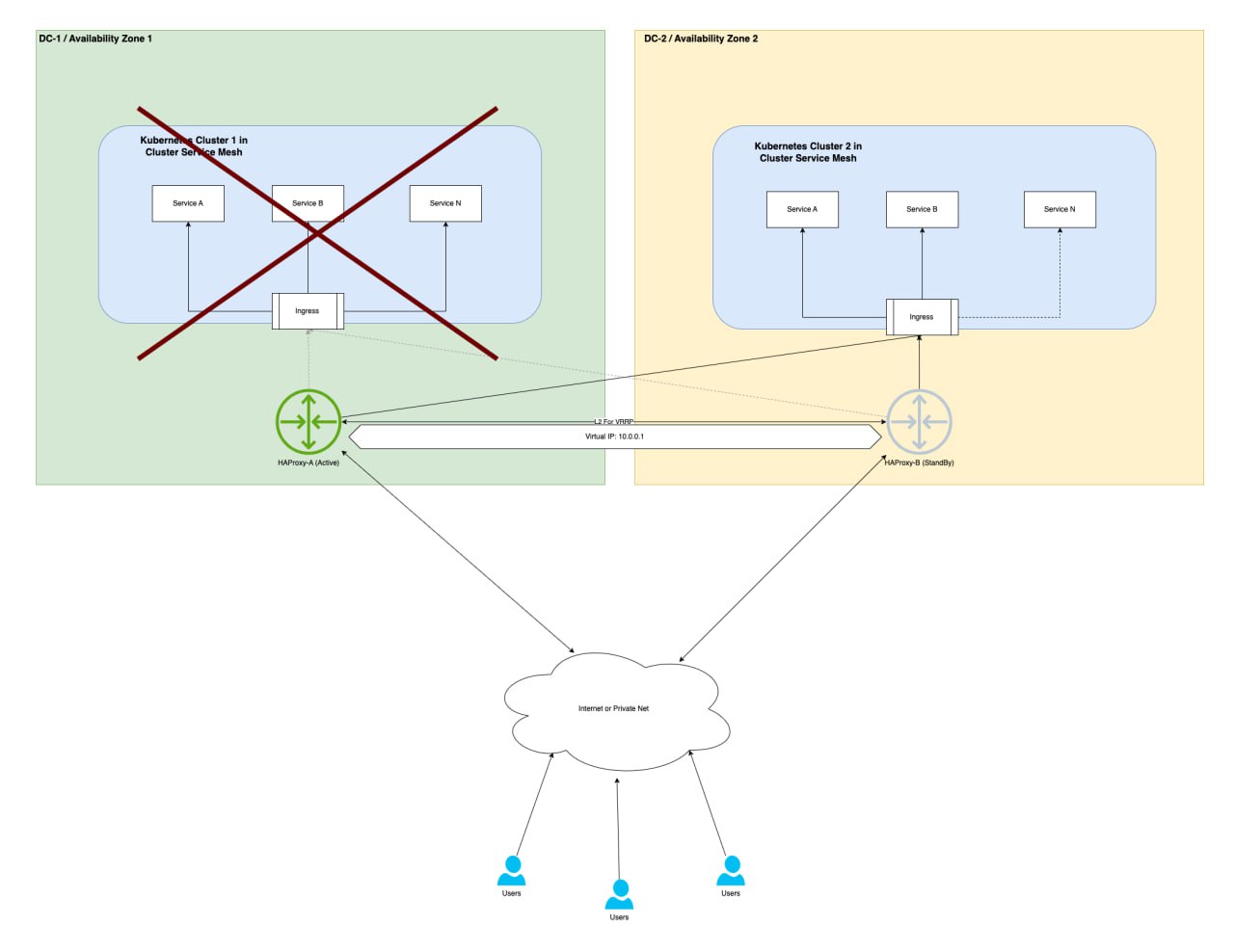
При VRRP, выделяется один VIP адрес, который переходит между балансировщиками нагрузки, в зависимости от их состояния. Для корректной работы VRRP протокола должна быть обеспечена L2 связанность между разнесенными дата центрами. VRRP используется для обеспечения работоспособности в режиме active-standby. То есть в один момент времени, только один балансировщик будет “активным”, а второй “запасным”. При падении основного балансировщика нагрузки, VIP адрес будет назначен на “запасной”, тем самым обеспечивается отказоустойчивость. При этом активный, в текущий момент времени, балансировщик, будет маршрутизировать трафик в оба дата-центра, тем самым решается поставленная задача работы в режиме active-active.
Для организации VRRP может использоваться keepalived на серверах с установленным HAProxy.
Минусы В предложенной схеме, HAProxy будет опираться на работоспособность ingress controller, а ingress controller в свою очередь на readiness ответы от запущенных сервисов: чего может быть недостаточно для обеспечения отказоустойчивости сервисов.
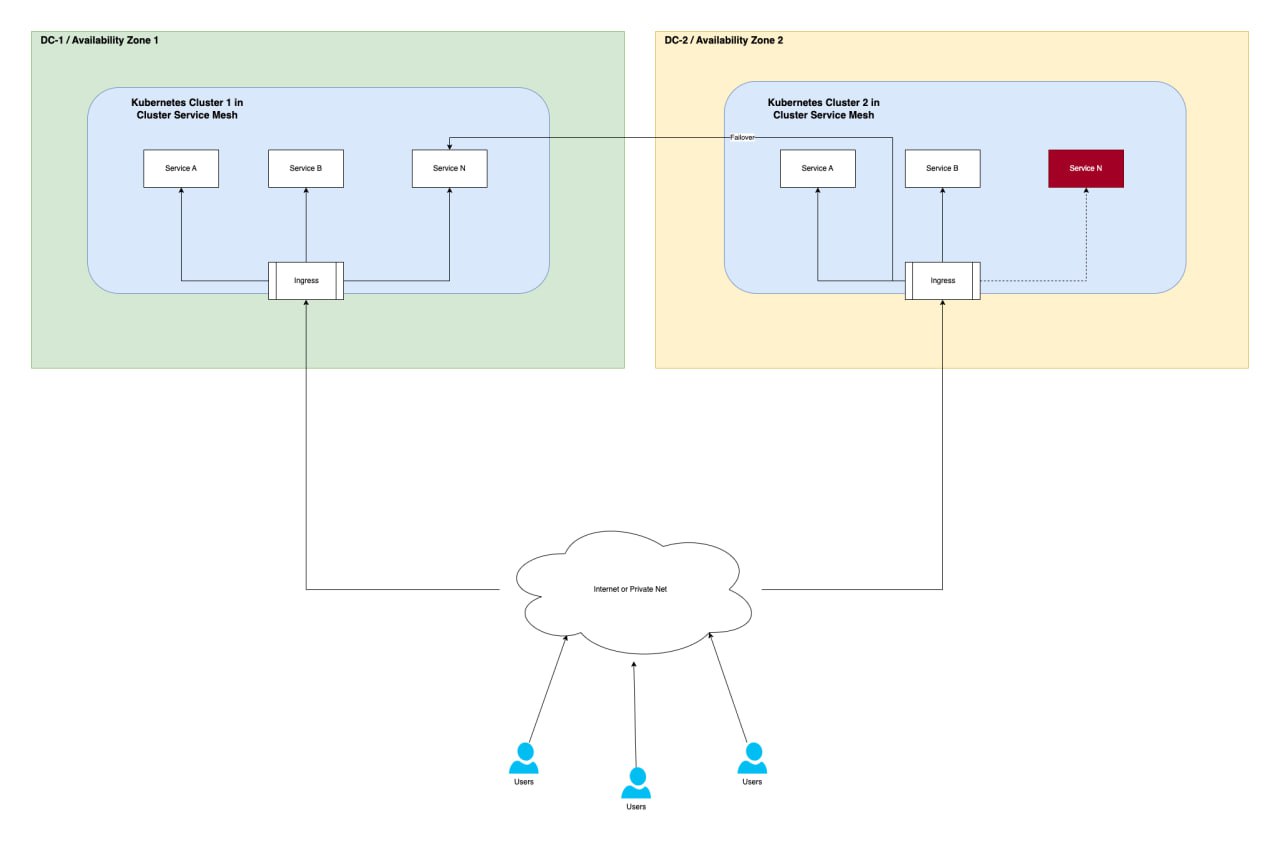
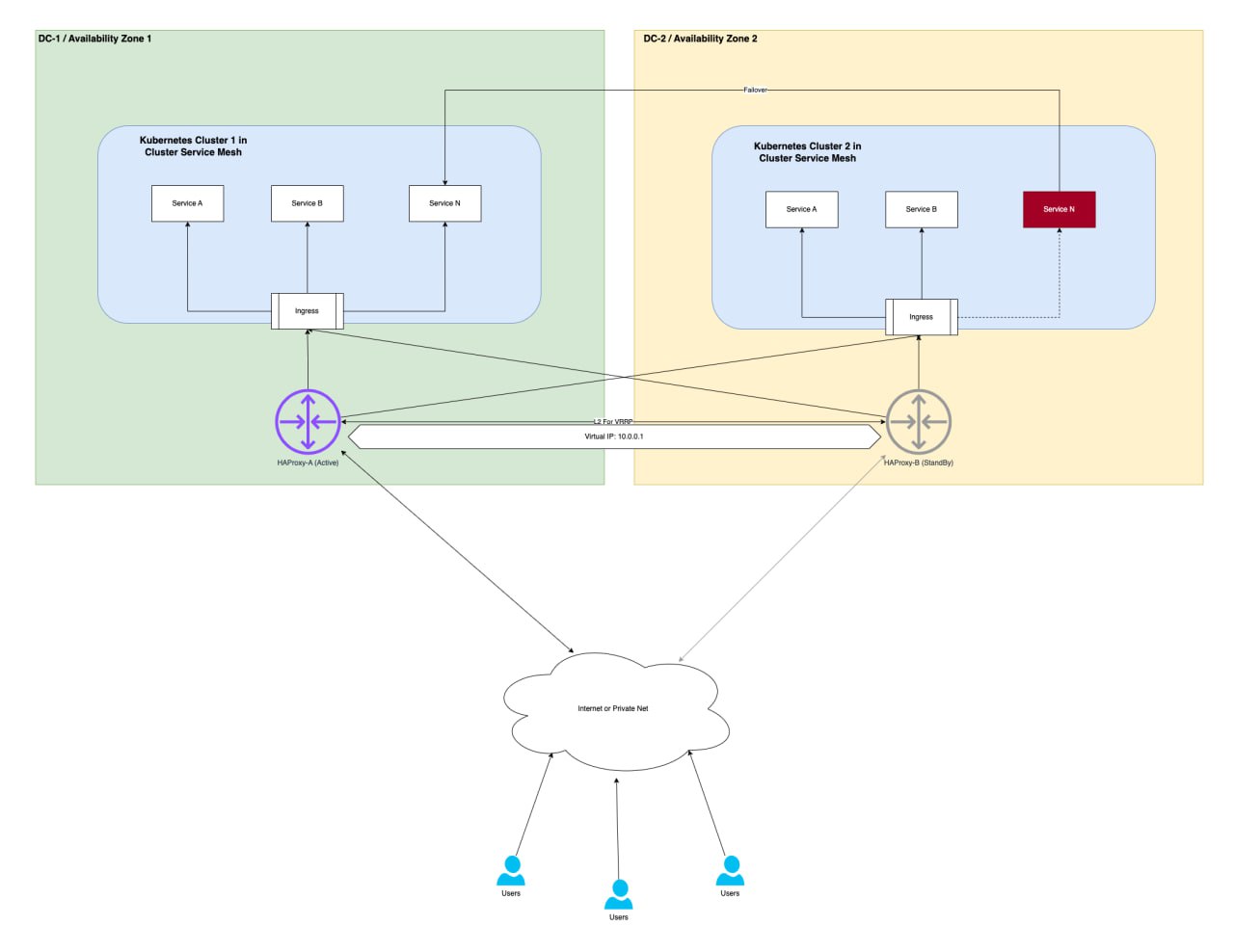
Возможные сценарии
Описание параметров
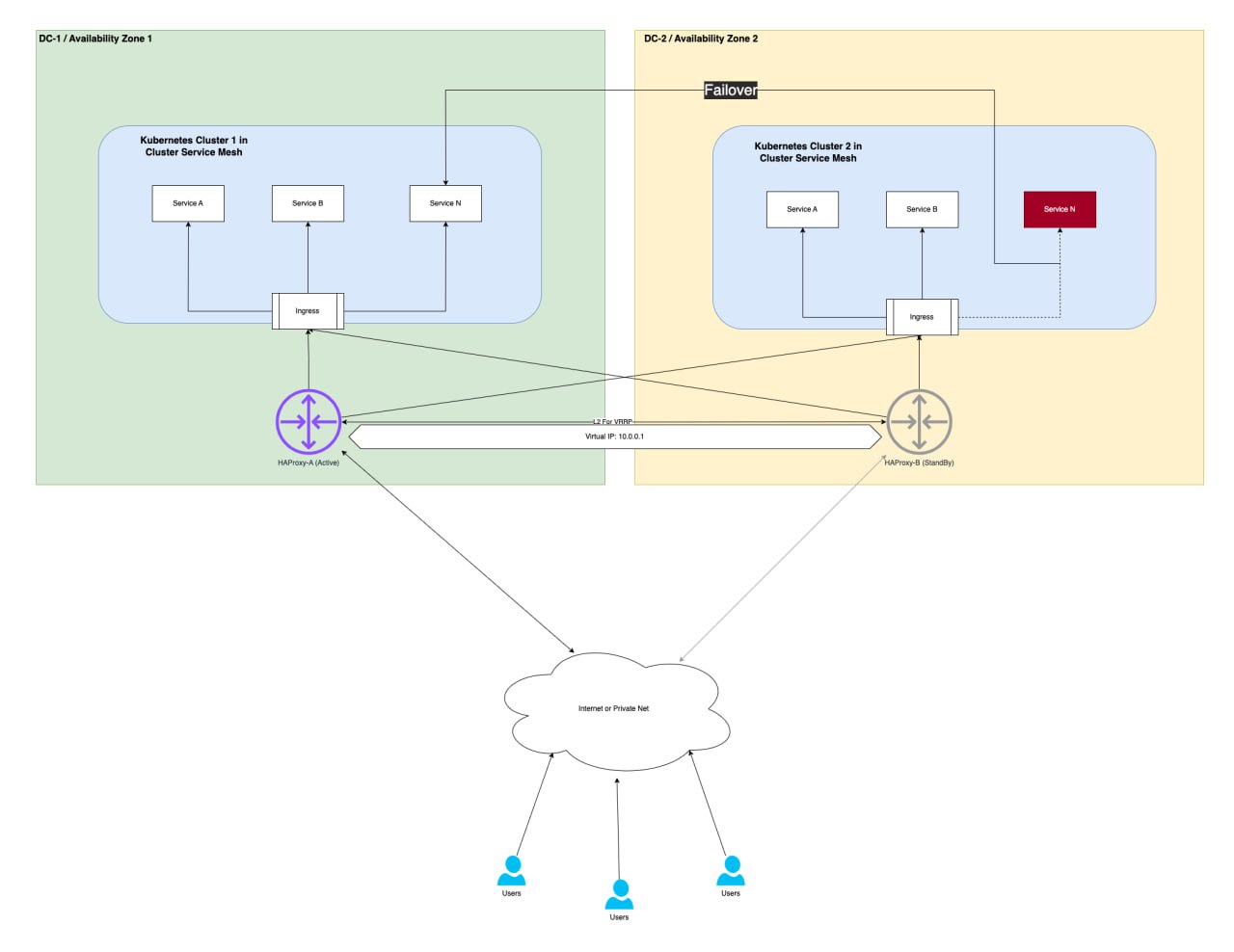
| При падении сервиса | HAProxy перестает на него направлять трафик, а балансировка осуществляется в доступный экземпляр в другом ДЦ |
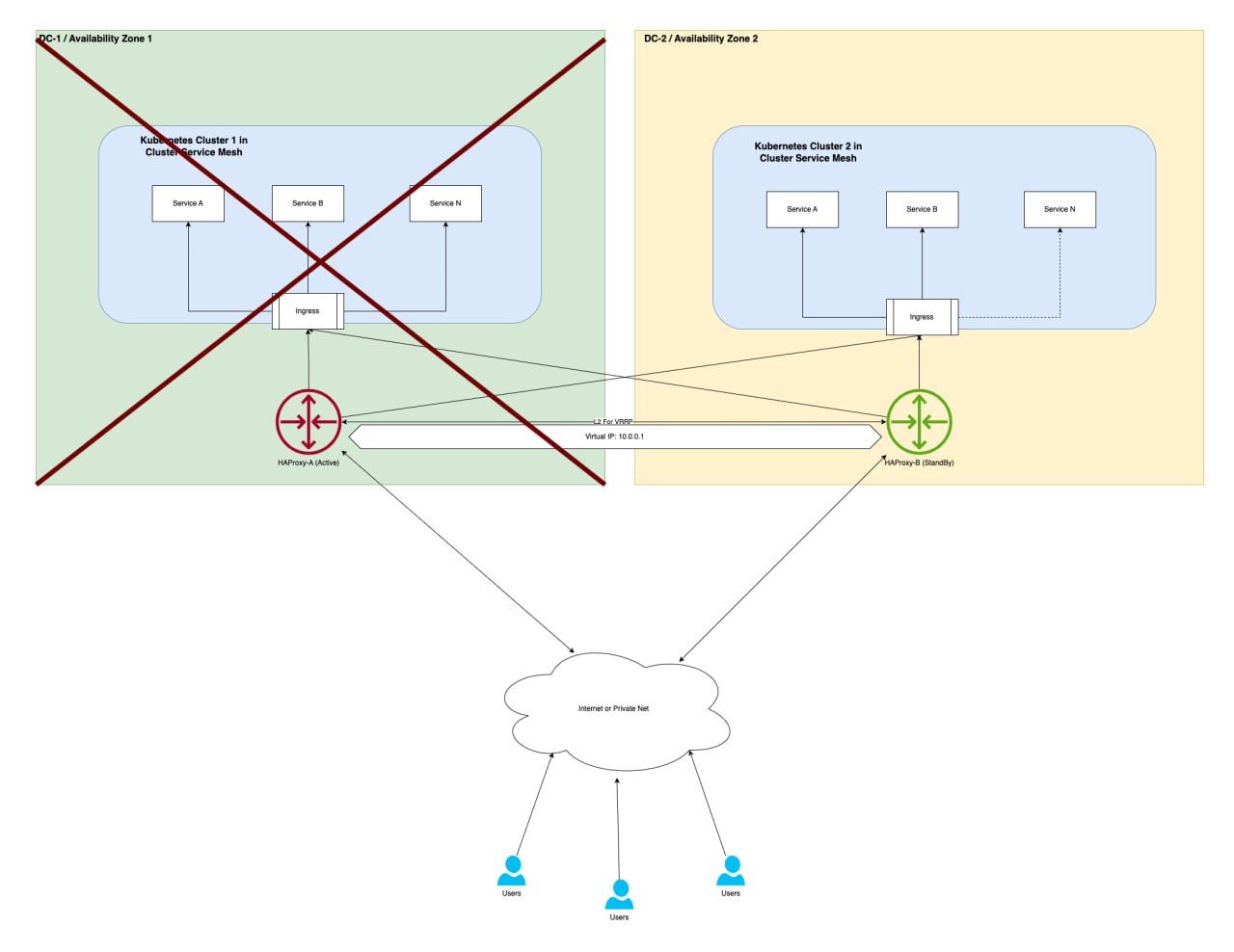
| При падении кластера | Весь трафик перенаправляется в другой ЦОД, а упавший кластер исключается из балансировки |
| При падении датацентра или HAProxy | Отрабатывает VRRP на HAProxy, VIP адрес переезжает и “запасной” экземпляр становится основным |
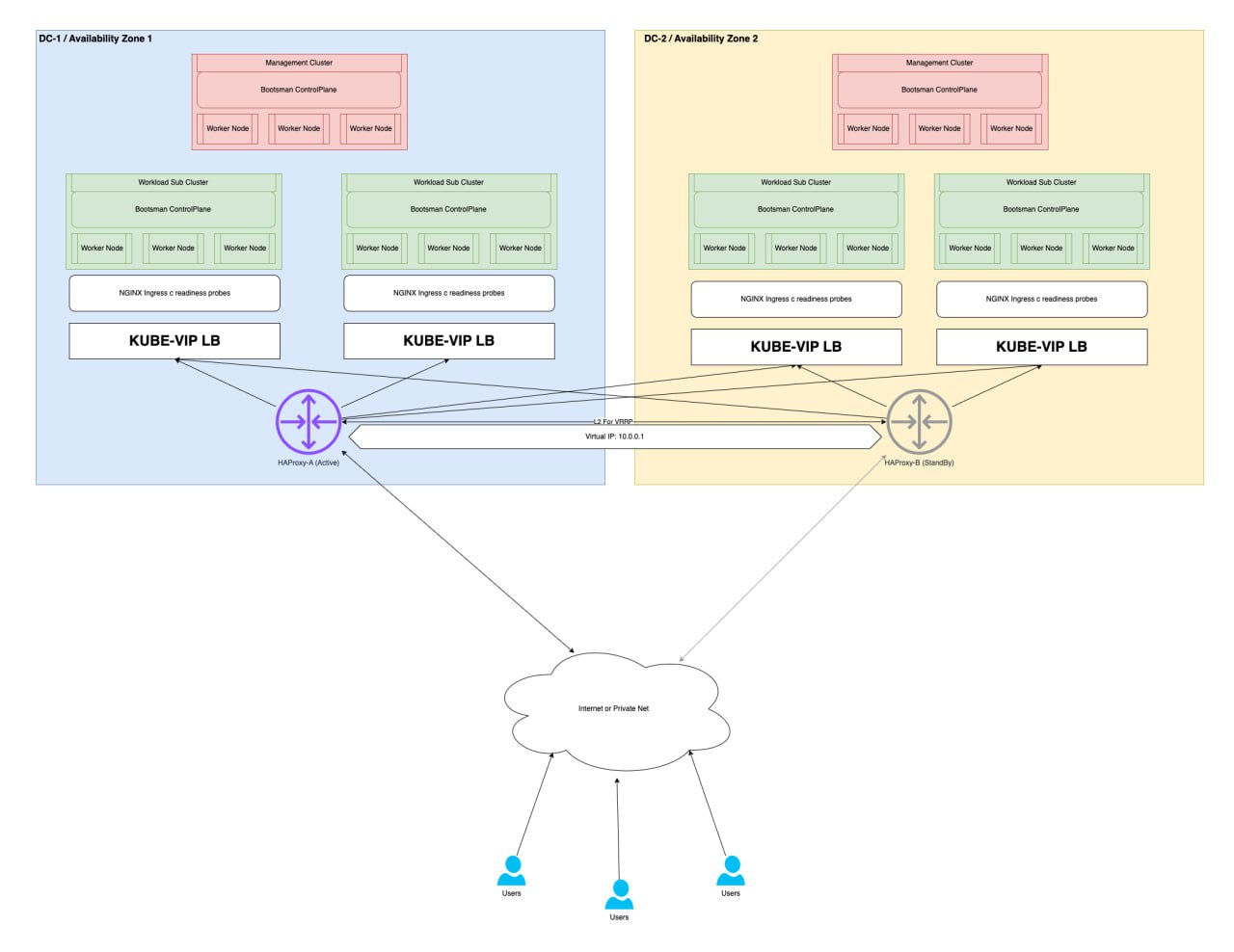
Рекомендуемое решение
Описание
По отдельности Cilium Cluster Mesh и VRRP+HAProxy имеют, описанные выше, ограничения. Совместив Cilium Cluster Mesh + HAProxy + VRRP, можно добиться высокой доступности точки внешней терминации, балансировки трафика и отказоустойчивость сервисов запущенных внутри Kubernetes.
Диаграмма решения Cluster Mesh + HAProxy + VRRP
Приложение 1. Диаграммы отказа по сценариям
Отказ датацентра или HAProxy
Отказ сервиса в кластере
Отказ кластера