Автоскейлинг в кластере
KEDA (Kubernetes Event-driven Autoscaling) позволяет автоматически масштабировать Kubernetes-объекты на основе событий, таких как нагрузка на процессор, память или другие метрики.
Основные возможности:
- Позволяет масштабировать приложения в реальном времени в зависимости от количества событий, поступающих в систему. Это позволяет оптимизировать использование ресурсов и обеспечивать отзывчивость системы.
- Интегрируется с различными поставщиками событий, такими как Apache Kafka, Azure Queue Storage, RabbitMQ и другими. Это обеспечивает гибкость в выборе источника данных для вашего приложения.
- Интегрируется с механизмом масштабирования Horizontal Pod Autoscaler в Kubernetes, что позволяет использовать их вместе для оптимального управления нагрузкой.
- Предоставляет различные параметры конфигурации, такие как минимальное и максимальное количество реплик, метрики для масштабирования и т. д., что позволяет настраивать его поведение под конкретные потребности приложения.*
Подключение модуля
Заметка
Общая информация по работе с модулями: Работа с модулями
Для установки модуля необходимо перейти в раздел Cluster Management и открыть его на редактирование
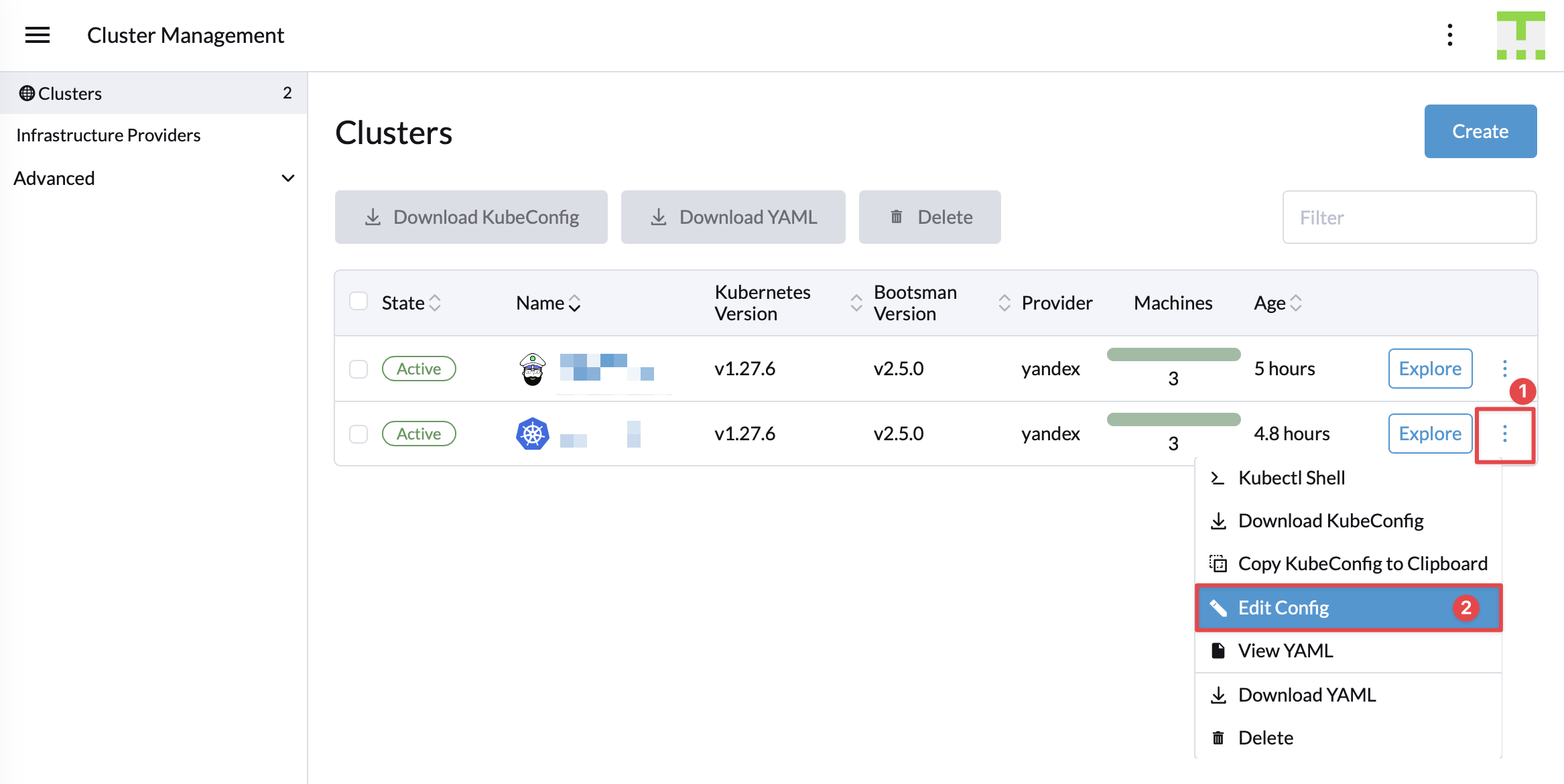
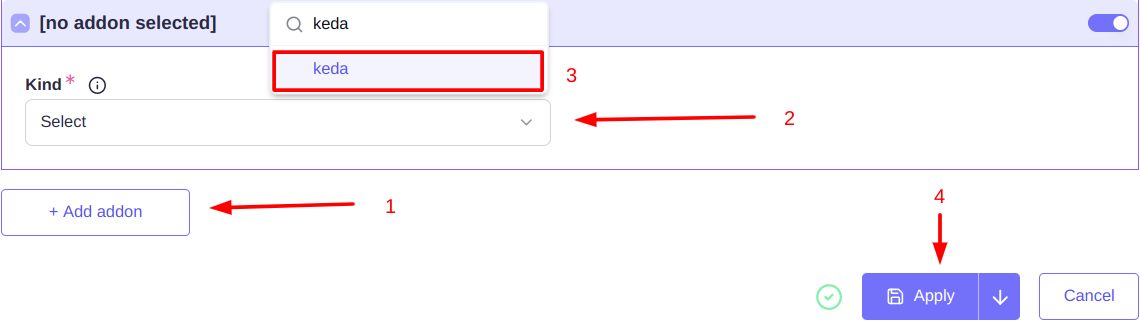
Где проскроллить вниз и добавить модуль keda и нажать кнопку "Apply".
Использование
Внимание!
Несколько разных ScaledObject не могут управлять одним объектом(scaleTarget). Для того чтобы масштабировать по нескольким правилам нужно все "triggers" указывать в одном ScaledObject
Автоскейлинг экземпляров приложения (pods)
Для автоматического масштабирования Deployment (и других контроллеров рабочей нагрузки: StatefulSet, CRDs) необходимо создать ScaledObject - ресурс содержащий параметры автоскейлинга и его цели.
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ${ SO_NAME }
namespace: ${ SO_NAMESPACE }
spec:
maxReplicaCount: ${ MAX_REPLICA_COUNT }
minReplicaCount: ${ MIN_REPLICA_COUNT }
scaleTargetRef:
apiVersion: ${ API_VERSION_TARGET_KIND }
kind: ${ TARGET_KIND }
name: ${ TARGET_NAME }
triggers: # Список триггеров для активации автоскейлинга целевых ресурсов. Ниже приведен пример такого триггера
- type: prometheus # Тип триггера
metadata:
serverAddress: http://rancher-monitoring-prometheus.cattle-monitoring-system.svc.cluster.local:9090 # Адрес источника
threshold: '100'
query: sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{namespace="default"} * on(namespace,pod) group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{namespace="default",workload_type="deployment",workload="my-deployment"}) by (workload, workload_type)
Описание параметров
| Имя параметра | Описание | Комментарий |
|---|---|---|
| ${SO_NAME} | Имя ресурса ScaledObject | Обязательный. |
| ${SO_NAMESPACE} | Namespace ScaledObject | Опциональный. Масштабируемое приложение должно находиться в одном namespace с конфигурацией ScaledObject. По умолчанию: default |
| ${MAX_REPLICA_COUNT} | Максимальное количество реплик целевого ресурса | Опциональный. По умолчанию: 100 |
| ${MIN_REPLICA_COUNT} | Минимальное количество реплик целевого ресурса | Опциональный. По умолчанию: 0 |
| ${API_VERSION_TARGET_KIND} | Версия API kind целевого ресурса | Опциональный. По умолчанию: apps/v1 |
| ${TARGET_KIND} | Тип (kind) объекта целевого ресурса | Опциональный. По умолчанию: Deployment |
| ${TARGET_NAME} | Имя целевого ресурса | Обязательный |
Ознакомится с полной спецификацией ScaledObject можно в официальной документации. Список всех триггеров для скейлинга целевого ресурса.
Примеры ScaledObject
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: my-deployment-scaledobject
namespace: default
labels:
deploymentName: dummy
spec:
maxReplicaCount: 5
minReplicaCount: 1
scaleTargetRef:
apiVersion: apps/v1 #Default: apps/v1
kind: Deployment #Default: Deployment
name: load
triggers:
- type: prometheus
metadata:
serverAddress: http://rancher-monitoring-prometheus.cattle-monitoring-system.svc.cluster.local:9090
threshold: '1'
query: sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{namespace="default"} * on(namespace,pod) group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{namespace="default",workload_type="deployment",workload="load"}) by (workload, workload_type)
Следующей командой можно запустить стресс-тест с Deployment, который будет маштабироваться в соответствии с конфигурацией ScaledObject
kubectl create deployment load --image=vish/stress --replicas 1 -- /stress --cpus 2 --mem-total 512M --logtostderr
> kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-my-deployment-scaledobject Deployment/load 1903m/1 (avg) 1 5 5 3m38s
> kubectl get hpa keda-hpa-my-deployment-scaledobject -o jsonpath="{.status.currentMetrics[*]}"
{"external":{"current":{"averageValue":"1909m"},"metric":{"name":"s0-prometheus","selector":{"matchLabels":{"scaledobject.keda.sh/name":"my-deployment-scaledobject"}}}},"type":"External"}
> kubectl get scaledobject my-deployment-scaledobject -n default -o jsonpath="{.status.health}"
{"s0-prometheus":{"numberOfFailures":0,"status":"Happy"}}>
Автоскейлинг узлов WorkerPool подчиненного кластера (nodes)
Keda позволяет автоматически масштабировать WorkerPool подчиненного кластера
Для этого сначала нужно получить ID подчиненного кластера:
> kubectl get clusters.provisioning.bootsman.tech **sub-example** -o=jsonpath='{.status.rancherClusterRef.name}'
c-m-wb84fv65
sub-example - имя подчиненного кластера.
Bootsman автоматически создает ClusterTriggerAuthentication и соответствующий секрет, при включении аддона Keda.
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ${ SO_NAME }
namespace: ${ SO_NAMESPACE }
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: ${ TRANSFER_HPA_OWNERSHIP }
validations.keda.sh/hpa-ownership: ${ HPA_OWNERSHIP }
autoscaling.keda.sh/paused: ${ PAUSED }
spec:
scaleTargetRef:
apiVersion: ${ API_VERSION_TARGET_KIND }
kind: ${ TARGET_KIND }
name: ${ TARGET_NAME }
pollingInterval: ${ POLLING_INTERVAL }
cooldownPeriod: ${ COOLDOWN_PERIOD }
minReplicaCount: ${ MIN_REPLICA_COUNT }
maxReplicaCount: ${ MAX_REPLICA_COUNT }
fallback:
failureThreshold: ${ FALLBACK_FAILURE_THRESHOLD }
replicas: ${ FALLBACK_REPLICAS }
triggers:
- type: prometheus
metadata:
authModes: "basic"
serverAddress: https://rancher.cattle-system/k8s/clusters/${ SUB-CLUSTER_ID }/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-prometheus:9090/proxy # Адрес сервера Prometheus. Необходимо обязательно указать ID кластера полученный в предыдущих шагах
unsafeSsl: "true"
query: sum(100 * avg(1 - rate(node_cpu_seconds_total{mode="idle",nodename=~".*-md-.*"}[1m])) by (nodename)) # Запрос Prometheus для мониторинга
threshold: "50" # Пороговое значение для срабатывания автомасштабирования
authenticationRef:
kind: ClusterTriggerAuthentication
name: keda-trigger-auth #Имя объекта ClusterTriggerAuthentication содержащего ссылку на секрет с токеном
Описание параметров
| Имя параметра | Описание | Комментарий |
|---|---|---|
| ${SO_NAME} | Имя ресурса ScaledObject | Обязательный. |
| ${SO_NAMESPACE} | Namespace ScaledObject | Опциональный. Объект WorkerPool должен находиться в одном namespace с конфигурацией ScaledObject. По умолчанию: default |
| ${TRANSFER_HPA_OWNERSHIP} | Передача существующего владения HPA данному объекту | Опциональный. По умолчанию: "true" |
| ${HPA_OWNERSHIP} | Проверка владения HPA на этом ScaledObject | Опциональный. По умолчанию: "true" |
| ${PAUSED} | Приостановка автомасштабирования объектов явно | Опциональный. По умолчанию: "false" |
| ${API_VERSION_TARGET_KIND} | Версия API kind целевого ресурса (WorkerPool) | Опциональный. По умолчанию: provisioning.bootsman.tech/v1alpha1 |
| ${TARGET_KIND} | Тип (kind) объекта целевого ресурса (WorkerPool) | Опциональный. По умолчанию: Workerpool |
| ${TARGET_NAME} | Имя WorkerPool'а подчиненного кластера, для которого мы создаем правило масштабирования | Обязательный |
| ${POLLING_INTERVAL} | Интервал для проверки каждого триггера в секундах. | Опциональный. По умолчанию: 30 |
| ${COOLDOWN_PERIOD} | Период ожидания после того, как последний триггер сообщил об активности, прежде чем масштабировать ресурс обратно до 0, в секундах. | Опциональный. По умолчанию: 300 |
| ${MAX_REPLICA_COUNT} | Максимальное количество реплик целевого ресурса | Опциональный. По умолчанию: 100 |
| ${MIN_REPLICA_COUNT} | Минимальное количество реплик целевого ресурса | Опциональный. По умолчанию: 0 |
| ${FALLBACK_FAILURE_THRESHOLD} | Количество неудачных попыток получить данные из источника | Опциональный. Обязательный если секция fallback используется |
| ${FALLBACK_REPLICAS} | Количество реплик в случае ошибки Keda | Опциональный. Обязательный если секция fallback используется |
Примеры ScaledObject
В примерах установлены следующие значения
$SUB_CLUSTER_ID = c-m-w4lfkvns
$TARGET_NAME = sub-example-worker
Средняя загрузка CPU на нодах более 80%
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cluster-a
namespace: default
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true"
validations.keda.sh/hpa-ownership: "true"
autoscaling.keda.sh/paused: "false"
spec:
scaleTargetRef:
apiVersion: provisioning.bootsman.tech/v1alpha1
kind: WorkerPool
name: sub-example-worker
pollingInterval: 10
cooldownPeriod: 150
minReplicaCount: 3
maxReplicaCount: 5
fallback:
failureThreshold: 3
replicas: 5
triggers:
- type: prometheus
metadata:
authModes: "basic"
serverAddress: https://rancher.cattle-system/k8s/clusters/c-m-w4lfkvns/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-prometheus:9090/proxy
unsafeSsl: "true"
query: sum(100 * avg(1 - rate(node_cpu_seconds_total{mode="idle",nodename=~".*-md-.*"}[1m])) by (nodename))
threshold: "50"
authenticationRef:
kind: ClusterTriggerAuthentication
name: keda-trigger-auth
Средняя загрузка RAM на нодах более 80%
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cluster-a
namespace: default
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true"
validations.keda.sh/hpa-ownership: "true"
autoscaling.keda.sh/paused: "false"
spec:
scaleTargetRef:
apiVersion: provisioning.bootsman.tech/v1alpha1
kind: WorkerPool
name: sub-example-worker
pollingInterval: 10
cooldownPeriod: 150
minReplicaCount: 3
maxReplicaCount: 5
fallback:
failureThreshold: 3
replicas: 5
triggers:
- type: prometheus
metadata:
authModes: "basic"
serverAddress: https://rancher.cattle-system/k8s/clusters/c-m-w4lfkvns/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-prometheus:9090/proxy
unsafeSsl: "true"
query: sum((1 - (node_memory_MemAvailable_bytes{nodename=~".*-md-.*"} / node_memory_MemTotal_bytes{nodename=~".*-md-.*"})) * 100)
threshold: "40"
authenticationRef:
kind: ClusterTriggerAuthentication
name: keda-trigger-auth
Среднее число подов на каждой ноде более 200
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cluster-a
namespace: default
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true"
validations.keda.sh/hpa-ownership: "true"
autoscaling.keda.sh/paused: "false"
spec:
scaleTargetRef:
apiVersion: provisioning.bootsman.tech/v1alpha1
kind: WorkerPool
name: sub-example-worker
pollingInterval: 10
cooldownPeriod: 150
minReplicaCount: 3
maxReplicaCount: 5
fallback:
failureThreshold: 3
replicas: 5
triggers:
- type: prometheus
metadata:
authModes: "basic"
serverAddress: https://rancher.cattle-system/k8s/clusters/c-m-w4lfkvns/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-prometheus:9090/proxy
unsafeSsl: "true"
query: sum(kubelet_running_pods{node=~".*-md-.*"}) OR sum(kubelet_running_pod_count{node=~".*-md-.*"})
threshold: "200"
authenticationRef:
kind: ClusterTriggerAuthentication
name: keda-trigger-auth
Пример нескольких правил масштабирования в одном ScaledObject:
ScaledObject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cluster-a
namespace: default
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true"
validations.keda.sh/hpa-ownership: "true"
autoscaling.keda.sh/paused: "false"
spec:
scaleTargetRef:
apiVersion: provisioning.bootsman.tech/v1alpha1
kind: WorkerPool
name: sub-example-worker
pollingInterval: 10
cooldownPeriod: 150
minReplicaCount: 3
maxReplicaCount: 5
fallback:
failureThreshold: 3
replicas: 5
triggers:
- type: prometheus
metadata:
authModes: "basic"
serverAddress: https://rancher.cattle-system/k8s/clusters/c-m-w4lfkvns/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-prometheus:9090/proxy
unsafeSsl: "true"
query: sum(100 * avg(1 - rate(node_cpu_seconds_total{mode="idle",nodename=~".*-md-.*"}[1m])) by (nodename))
threshold: "50"
authenticationRef:
kind: ClusterTriggerAuthentication
name: keda-trigger-auth
- type: prometheus
metadata:
authModes: "basic"
serverAddress: https://rancher.cattle-system/k8s/clusters/c-m-w4lfkvns/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-prometheus:9090/proxy
unsafeSsl: "true"
query: sum((1 - (node_memory_MemAvailable_bytes{nodename=~".*-md-.*"} / node_memory_MemTotal_bytes{nodename=~".*-md-.*"})) * 100)
threshold: "40"
authenticationRef:
kind: ClusterTriggerAuthentication
name: keda-trigger-auth